

EPFL, Lausanne, Switzerland, 29-31 May 2017

High-throughput computing (HTC) is emerging as an effective methodology in computational materials science for the discovery of novel materials and the optimisation of selected properties. Its adoption is spreading rapidly at the point that HTC is becoming an essential tool for computational materials scientists.
The aim of the tutorial was to introduce young researchers and more experienced practitioners to HTC, with hands-on tutorials based on the open-source high-throughput platform AiiDA (http://www.aiida.net), complemented by four invited keynote talks to overview the diverse application fields of HTC.
We report here a summary of what has happened.
Report
The tutorial was targeted at about 40 students, postdocs, and researchers interested in applying high-throughput computations in their research, and in particular to those interested in learning how to use the AiiDA platform.
It started in the morning of Monday 29th May. After the registration formalities and a short introduction by the workshop organizers, Giovanni Pizzi (EPFL) gave a first introduction lecture on AiiDA and the design concepts behind it, essential to understand the code and more generally to efficiently manage high-throughput calculations: the ADES model, the concepts of data provenance and reproducibility, and how these can be achieved using AiiDA.
Hands-on sessions
After the coffee break, we started the first of a series of hands-on sessions with AiiDA. The room was large enough to host all participants, each of them working either on its own laptop, or on laptops provided by EPFL. Each session was always introduced by the instructors, who briefly explained the aim of the session. The detailed instructions on the tasks to achieve were then provided on a printed booklet (and also on a PDF file), so that participants could learn at their own pace. Some Hands-on sessions were supported with jupyter-notebooks, which the participants had to adapt. Eight instructors plus the organizers (see list below) were available throughout all sessions to answer specific questions from the participants.
Participants looked extremely interested and thrilled in learning the code. Sessions were interleaved with invited talks (see below) and with coffee breaks.

Invited highlight talks
The workshop, however, was also focused more generally on teaching general techniques to be used in high-throughput calculation, independent of the code used. For this reason, we have invited four experts active in the domain of high-throughput simulations.
The first talk, on Monday afternoon, was given by Dr. Thomas Bligaard (SLAC National Accelerator Laboratory / Stanford University, USA), with the title “Accelerating high-throughput simulations using machine learning methods”.
The second talk by Prof. Stefano Sanvito (Trinity College Dublin, IRL) was on Tuesday morning and it was titled “High-throughput electronic structure theory: do we need to calculate always everything?”.

Prof. Chris J. Pickard (Univ. of Cambridge, UK) gave a talk on Tuesday evening on “Random search as high throughput computation”.

The final highlight talk was on Wednesday afternoon given by Prof. Marco Fornari (Central Michigan University, USA) with the title “Structuring intuition with theory: The high-throughput way”.

All speakers discussed extremely interesting results from their research, showing in particular how they performed computational searches of materials inside known classes, how filtering of results could be achieved to reduce the number of candidates and perform very expensive calculations only on a subset of them, and explaining methods that can be applied to extract information from simulations using machine-learning techniques.
Workshop structure, social events and support
Each morning started with a half-an-hour discussion session, where each participant was encouraged to ask questions either on technical questions on the AiiDA code or, more generally, on its personal high-throughput research. It was interesting to see how the participants were discussing among themselves on different ways to solve common problems encountered when running large numbers of simulations.
A social dinner took place on Tuesday evening at the restaurant “Le Debarcadère” in Saint Sulpice, Lausanne. We were lucky enough to have a very nice and pleasant weather, that allowed us to have dinner on the terrace on the lakeside, facing the Alps, with a beautiful natural landscape and having lots of great scientific discussions.
Finally, it is worth mentioning that, thanks to the generous support of funding entities (Psi-K, MARVEL and MaX), it has been possible to provide financial support for the accommodation in a hotel on campus to 11 participants (additional to covering the organization expenses, all coffee breaks, the standing dinner during the poster session, and the social dinner on Tuesday evening). This has made it possible for some participants to take part to the tutorial.
Moreover, in order to encourage discussions and exchange between participants, a poster session was organised in the evening of the first day (29nd May), together with a standing dinner. 10 posters were presented, and the participants seemed very interested in discussing in detail each other’s work.
Tutorial details
The tutorial and the jupyter-notebooks that the instructors prepared in the weeks preceding the event allowed for a smooth learning curve, and got participants interested to learn more rather than bored by technical details.
For this reason, from the very first session, users started to use the code directly, without any initial session on how to install the code. To achieve this, the tutorial was running on Amazon AWS machines, that provided a very consistent and homogeneous environment to all participants, giving at the same time to each of them a different machine to test, learn and practice.
After the end of the tutorial the virtual machines have also published online as a downloadable VirtualBox appliance (on http://www.aiida.net/tutorials). In this way, it becomes extremely easy for participants to run again the tutorial in the future (e.g., optional parts). Most importantly, also people who could not attend the tutorial can profit of the learning material and start learning the code with almost zero time required for initial setup (it is just needed to install VirtualBox, download the appliance and start it).
Finally, both the instructor sessions and the invited speaker talks have been recorded and will be available online soon on the Materials Cloud youtube channel.
Tutorial content
The first sessions focused both on understanding the basic commands to interact with the code, while at the same time participants were getting acquainted with the concept of calculation graphs (the way AiiDA internally stores calculations, data and their relationships).
Later, they started to learn how to submit calculations (using Quantum ESPRESSO) with AiiDA. Since in real life errors always occur, we decided to avoid to present a “perfect” tutorial that always works. Instead, the instructions were explicitly asking the user to submit a ‘wrong’ calculation that (for various reasons) would crash, to then teach the participants how to understand where things went wrong, and how to fix potential problems.
The second day was focused on more advanced topics. First, on how to efficiently query calculations in the database. A test database comprising about 300 calculations on a family of perovskites was provided, and participants could perform various queries to understand the data, with the final aim of producing a plot to understand which perovskites were metallic, and which were magnetic.
The second very important topic was “workflows/workchains”. We first started by introducing the concept of provenance, why it is important to keep track of what has happened, and how to run simulations without “breaking” it. Examples were shown from very simple use cases (like an equation of state). Participants learned how, with a single line, one can ask AiiDA to store the representation of a python function in the database for later querying (using ‘workfunctions’) and how to write full-fledged workflows to automatically obtain a result of interest that originates from a long sequence of calculations.
The session on workflows/workchains extended into the morning of the final (third) day, that ended with an explanation of how to install AiiDA and extend it with plugins.
We also had a presentation by Dr. Nicolas Mounet, that showed a real-case study from his research: using AiiDA, he could screen over 200,000 materials from 3D databases (ICSD and COD) to filter out only those that are layered (~6000). Those were further refined with extensive DFT calculations to calculate the binding energy and produce a very interesting database of those (~1800) that are indeed weakly (Van der Waals) bonded and are potentially realisable in the lab using exfoliation techniques.
Results of the feedback form
The feedback received from the participants has been extremely positive. We report below the main results of the feedback form.
The next two plots compare the self-assessed level of knowledge of AiiDA of the participants before and after the tutorial. Remarkably, participants with a “poor” level of knowledge, which represented the relative majority before the tutorial, were no longer present after the tutorial. The vast majority of the self-evaluations after the tutorial was “satisfactory” or better.

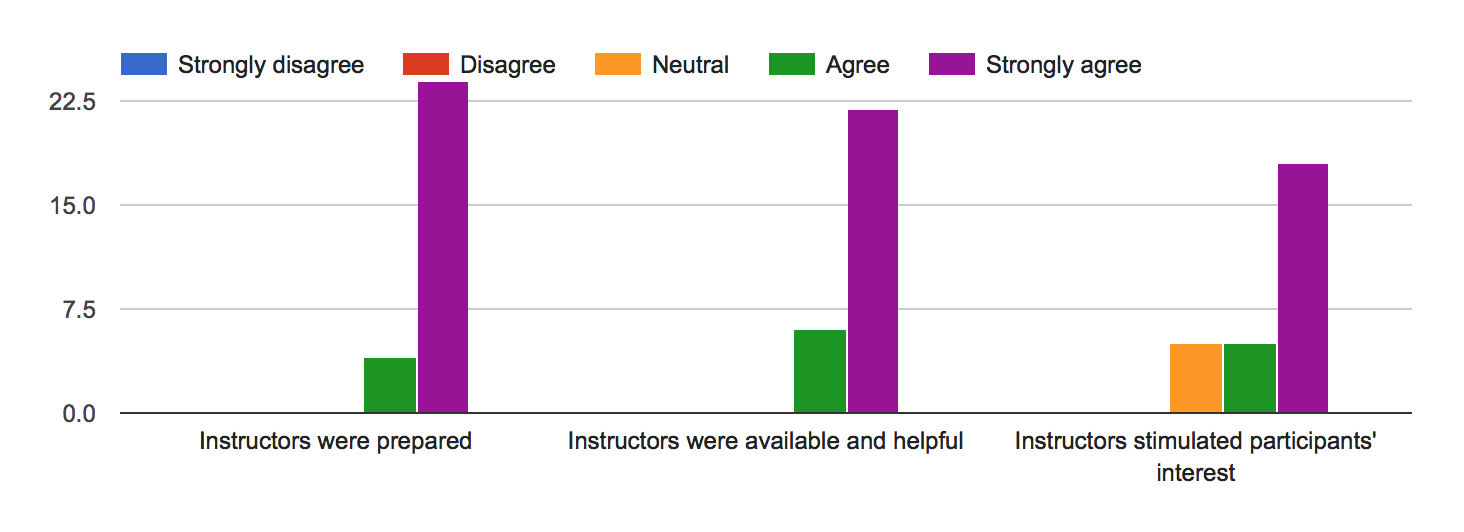
The following series of plots reports on the evaluations that the instructors received from the participants. The distribution of the responses suggests that the instructors were prepared, available, and capable to effectively motivate the participants.
Finally, 92.8% of the participants declared that they would strongly recommend their colleagues to participate to a similar tutorial on high-throughput computations using AiiDA. Also, 75% of the participants said they would like to participate in advanced AiiDA tutorials on topics like workflow development.
Additional information
Workshop organizers
- Giovanni Pizzi – EPFL, Switzerland
- Fernando Gargiulo – EPFL, Switzerland
- Andrea Ferretti – CNR, Istituto Nanoscienze, Italy
- Jens Bröder – IAS, Forschungszentrum Jülich, Germany
Tutorial instructors
- Fernando Gargiulo – EPFL, Switzerland
- Sebastiaan Huber – EPFL, Switzerland
- Leonid Kahle – EPFL, Switzerland
- Nicolas Mounet – EPFL, Switzerland
- Giovanni Pizzi – EPFL, Switzerland
- Martin Uhrin – EPFL, Switzerland
- Snehal Waychal – EPFL, Switzerland
- Spyros Zoupanos – EPFL, Switzerland
Invited highlight talks
- Thomas Bligaard (Stanford University, USA): “Accelerating high-throughput simulations using machine learning methods”
- Stefano Sanvito (Trinity College Dublin, IRL): “High-throughput electronic structure theory: do we need to calculate always everything?”
- Chris J. Pickard (Univ. of Cambridge, UK): “Random search as high throughput computation”
- Marco Fornari (Central Michigan University, USA): “Structuring intuition with theory: The high-throughput way”
Program
The program is available online at: http://nccr-marvel.ch/en/events/aiida-tutorial-may-2017
Pictures of the event
Additional pictures of the event can be found on the AiiDA facebook page.
List of participants
- Chiheb Ben Mahmoud
- Marco Borelli
- Gloria Capano
- Jin Hyun Chang
- Marco Di Gennaro
- Vladimir Dikan
- Daniele Dragoni
- Karim Elgammal
- Daniel Hollas
- Jianxing Huang
- Yi Hu
- Till Junge
- Maja-Olivia Lenz
- Francesco Libbi
- Xiangyue Liu
- Simon Loftager
- Pierre-François Lory
- Giuliana Materzanini
- Daniel Gosálbez Martínez
- Felix Musil
- Yasuaki Okada
- Yashasvi Singh Ranawat
- Chiara Ricca
- Norma Rivano
- Ole Schütt
- Mehdi Sedighi
- Gregor Simm
- Jagoda Slawinska
- Štěpán Sršeň
- Andreas Stamminger
- Oliver Strickson
- Florian Thoele
- Michele Visciarelli
- Weiqi Wang
- QuanSheng Wu
- Pengxiang Xu
- Binglun Yin